
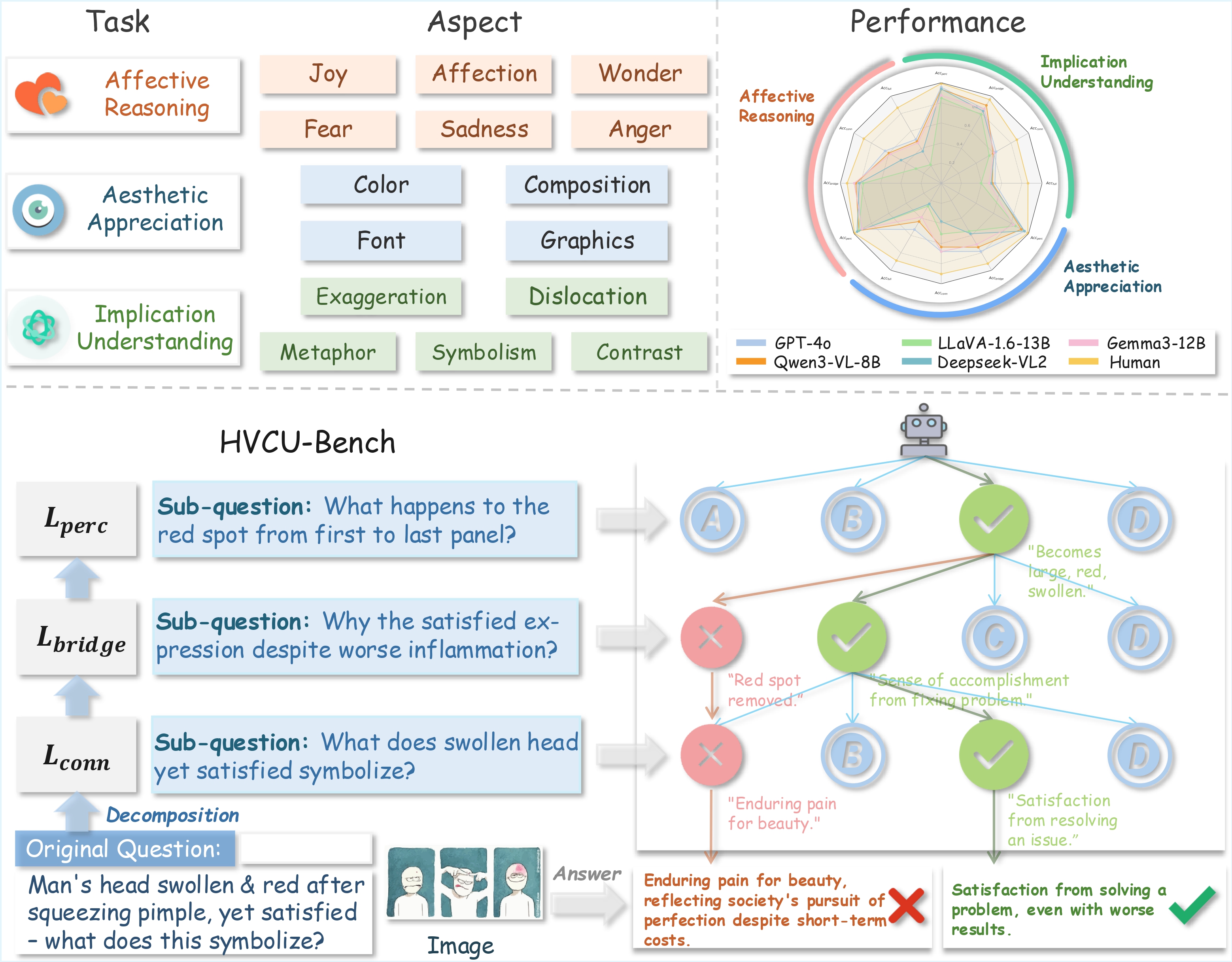

Level 1 -- Perception
Question: What is the primary method of communication used by the characters in the comic
strip?
A. Characters speak dialogue shown in speech bubbles.
B. They use only non-verbal actions like gestures and facial expressions.
C. Their communication is shown through thought bubbles above their heads.
D. A narrator provides descriptions of their thoughts and actions.
Answer: A
Level 2 -- Bridge
Question: Based on the sequence of events in the comic, what is the most direct reason the
yellow horse decides to become taller?
A. To gain a better vantage point for observing its surroundings.
B. To explore its own potential for extreme physical transformation.
C. To satisfy the blue horse's stated dating preference for tall individuals.
D. To develop a more imposing physique for self-defense.
Answer: C
Level 3 -- Connotation
Question: What could the abrupt transformation of the shorter character into a giraffe in
the final panel of the comic strip symbolize in terms of social commentary?
A. It symbolizes the importance of personal growth and improvement.
B. It represents a critique of the quest for physical perfection and the extremes to which people
will go to achieve it.
C. The transformation illustrates the beauty of embracing one's unique nature rather than
conforming.
D. The character symbolizes the absurdity of changing oneself to meet others' arbitrary
standards.
Answer: D













